Understanding your MMM: Sensitivity Analysis and Marginal Effects#
Extracting insights to drive business decisions is a primary goal of any MMM. PyMC-Marketing already offers a powerful suite of tools for this, including:
Driver contributions: Understanding how much each channel or factor is contributing to the outcome.
Return on Ad Spend (ROAS): Quantifying the financial return of your media investments.
Saturation curves: Visualizing how the impact of media spend changes at different spend levels (e.g., diminishing returns).
However, in many real-world cases, we want to go beyond these summaries. Marketers and analysts frequently ask:
“What would have happened if we had spent 10% less on media last month?”
“What would the effect of lowering the free shipping threshold by $5 have been?”
“Are we still getting good incremental returns at current spend levels, or have we hit diminishing returns?”
These questions focus on hypothetical scenarios of what would have happened under different conditions. As such, they are a clear form of sensitivity analysis. Given that we focus on retrospective predictions, these questions are “Step 3” on Pearl’s causal ladder (see the MMMs and Pearl’s ladder of causal inference docs). The basic idea is that we can use our model (and what it has learned from the data) to simulate how the outcome would have changes under various peterbations of the driver variables.
Rather than just considering a single peterbation (e.g., “what if we had spent 10% less on a given media channel”), sensitivity analysis allows us to explore a range of scenarios. So instead we could evaluate our predictions given a sweep of possible peterbations. For example, “what if we had spent [0.5, 0.75, 1.0, 1.25, 2.0] times as much on a given media channel?”
We introduce a flexible tool that allows you to:
Perform counterfactual sweeps across a range of predictor values (e.g., scaling media spend up/down or adjusting business levers like pricing).
Visualize both the total expected impact of these interventions.
Compute marginal effects—showing the instantaneous rate of change in the outcome as you adjust a predictor.
This approach complements the built-in PyMC-Marketing tools by providing scenario-based insights that help you answer “what if?” questions with precision and clarity.
Setting the scene with an example dataset#
In this example, we model weekly sales for a direct-to-consumer (DTC) brand that invests in influencer marketing while also adjusting its free shipping policy to drive conversions.
Our media variable is Influencer Spend, which typically exhibits non-linear effects due to factors like audience saturation and delayed impact, making it a good candidate for adstock and saturation transformations.
As a control variable, we include the Free Shipping Threshold — the minimum order value required for customers to qualify for free shipping. This is a fully controllable business lever and is expected to have a more linear relationship with sales: lowering the threshold generally increases conversion rates in a predictable way.
By examining the marginal effects of media spend and shipping policy, we can provide actionable insights into how each lever contributes to overall performance.
import warnings
import arviz as az
import graphviz as gr
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from pymc_marketing.mmm import (
GeometricAdstock,
LogisticSaturation,
)
from pymc_marketing.mmm.multidimensional import MMM
from pymc_marketing.mmm.transformers import geometric_adstock, logistic_saturation
warnings.filterwarnings("ignore", category=FutureWarning)
az.style.use("arviz-darkgrid")
plt.rcParams["figure.figsize"] = [12, 7]
plt.rcParams["figure.dpi"] = 100
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format = "retina"
seed: int = sum(map(ord, "ladder"))
rng: np.random.Generator = np.random.default_rng(seed=seed)
The autoreload extension is already loaded. To reload it, use:
%reload_ext autoreload
So our causal MMM will look like this:
Show code cell source
g = gr.Digraph()
g.node(name="Sales", label="Sales")
g.node(name="Influencer Spend", label="Influencer Spend")
g.node(name="Shipping Threshold", label="Shipping Threshold")
g.node(name="Seasonality", label="Seasonality")
g.node(name="Trend", label="Trend")
g.edge(tail_name="Influencer Spend", head_name="Sales")
g.edge(tail_name="Shipping Threshold", head_name="Sales")
g.edge(tail_name="Seasonality", head_name="Sales")
g.edge(tail_name="Trend", head_name="Sales")
g

Why Marginal Effects Matter: going beyond raw media curves#
In Media Mix Models (MMM), we’re often interested in understanding how each marketing input (like advertising spend) drives business outcomes. A common way to explore this is by looking at the inferred response curves, such as the saturation curve for media spend. These curves show how total sales respond to increasing investment, accounting for effects like diminishing returns and adstock.
But while these plots are useful, they can be misleading or incomplete when used in isolation.
The reason? Response curves tell you the absolute level of impact across different spend amounts, but they don’t directly tell you the incremental impact of a small change in spend at any given point. This distinction is crucial. For example:
A saturation curve might look steep at low spend levels and flatten out at higher spend—but the exact slope at a specific point (e.g., $50,000 per week) tells you the real-world payoff of spending an extra $1,000 right now.
In cases where multiple inputs are at play (like media spend and pricing changes), response curves for one variable don’t show you how interactions or current levels of other variables might affect its marginal impact.
Marginal effects zero in on this slope—the instantaneous rate of change. They answer questions like:
How much additional sales do I gain if I increase influencer spend by 10% next week?
What’s the expected lift if I lower the free shipping threshold by $5 right now?
These insights are only accessible through marginal effects because they reflect the dynamic, context-sensitive responsiveness of the model:
For media inputs with non-linear transformations (like adstock + saturation), marginal effects show how effectiveness varies across the spend range—revealing whether you’re still in the high-ROI zone or have hit diminishing returns.
For controllable non-media levers (like pricing or shipping policies), marginal effects provide precise, actionable estimates for how tweaks to these levers impact outcomes—even if their overall relationship is more linear.
In other words, while a response curve is like a map of the terrain, marginal effects tell you whether it’s worth climbing that next hill. They enable surgical precision in decision-making, ensuring that marketers don’t just see where their efforts sit on a curve—but understand whether pushing harder in a particular direction is still worthwhile.
By incorporating marginal effects into MMM outputs, we move from a static understanding of media performance to a dynamic, context-aware view that directly informs resource allocation and strategic adjustments.
Generate simulated data#
Show code cell source
def apply_transformations(df, channel, alpha, lam):
"""Apply geometric adstock and saturation transformations."""
adstocked = geometric_adstock(
x=df[channel].to_numpy(), alpha=alpha, l_max=8, normalize=True
).eval()
saturated = logistic_saturation(x=adstocked, lam=lam).eval()
return saturated
def forward_pass(df_in, params):
"""Run predictor variables through the forward pass of the model.
Given a dataframe with spend data columns and control variables, run this through the
transformations and return the response variable `y`.
"""
df = df_in.copy()
# Apply transformations to channels and calculate y
df["y"] = params["amplitude"] * (
df["intercept"]
+ df["trend"]
+ df["seasonality"]
+ sum(
params["beta"][i]
* apply_transformations(
df, params["channels"][i], params["alpha"][i], params["lam"][i]
)
for i in range(len(params["channels"]))
)
+ params["gamma"] * df["shipping_threshold"] # Include shipping_threshold
+ df["epsilon"]
)
return df
df = pd.DataFrame(
data={
"date": pd.date_range(
start=pd.to_datetime("2019-04-01"),
end=pd.to_datetime("2021-09-01"),
freq="W-MON",
)
}
).assign(
year=lambda x: x["date"].dt.year,
month=lambda x: x["date"].dt.month,
dayofyear=lambda x: x["date"].dt.dayofyear,
t=lambda x: range(x.shape[0]),
)
n_rows = df.shape[0]
# Media data: influencer spend
influencer_spend = rng.uniform(low=0.0, high=1.0, size=n_rows)
df["influencer_spend"] = np.where(
influencer_spend > 0.9, influencer_spend, influencer_spend / 2
)
# Control variable: shipping threshold
df["shipping_threshold"] = 25.0
df["shipping_threshold"].iloc[-12:] = (
20.0 # Reduced shipping threshold in the last 12 weeks
)
# Intercept, trend, seasonality components
df["intercept"] = 2.0
df["trend"] = (np.linspace(start=0.0, stop=50, num=n_rows) + 10) ** (1 / 4) - 1
df["cs"] = -np.sin(2 * 2 * np.pi * df["dayofyear"] / 365.5)
df["cc"] = np.cos(1 * 2 * np.pi * df["dayofyear"] / 365.5)
df["seasonality"] = 0.5 * (df["cs"] + df["cc"])
# Noise - can be considered as the effects of unobserved variables upon sales
df["epsilon"] = rng.normal(loc=0.0, scale=0.25, size=n_rows)
params = {
"channels": ["influencer_spend"],
"amplitude": 1.0,
"beta": [3.0],
"lam": [4.0],
"alpha": [0.4],
"gamma": -0.1, # Weight for shipping_threshold
}
df = forward_pass(df, params)
/var/folders/7q/tb5r85wd19l3fplnxjyfdn7r0000gp/T/ipykernel_41621/2986297912.py:63: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
df["shipping_threshold"].iloc[-12:] = (
And here are the first 5 rows of the synthetic dataset:
df.head()
| date | year | month | dayofyear | t | influencer_spend | shipping_threshold | intercept | trend | cs | cc | seasonality | epsilon | y | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2019-04-01 | 2019 | 4 | 91 | 0 | 0.918883 | 25.0 | 2.0 | 0.778279 | -0.012893 | 0.006446 | -0.003223 | -0.118826 | 2.561363 |
| 1 | 2019-04-08 | 2019 | 4 | 98 | 1 | 0.230898 | 25.0 | 2.0 | 0.795664 | 0.225812 | -0.113642 | 0.056085 | 0.064977 | 2.264874 |
| 2 | 2019-04-15 | 2019 | 4 | 105 | 2 | 0.254486 | 25.0 | 2.0 | 0.812559 | 0.451500 | -0.232087 | 0.109706 | -0.020269 | 1.998208 |
| 3 | 2019-04-22 | 2019 | 4 | 112 | 3 | 0.035995 | 25.0 | 2.0 | 0.828993 | 0.651162 | -0.347175 | 0.151993 | 0.400209 | 1.701116 |
| 4 | 2019-04-29 | 2019 | 4 | 119 | 4 | 0.336013 | 25.0 | 2.0 | 0.844997 | 0.813290 | -0.457242 | 0.178024 | 0.057609 | 2.003646 |
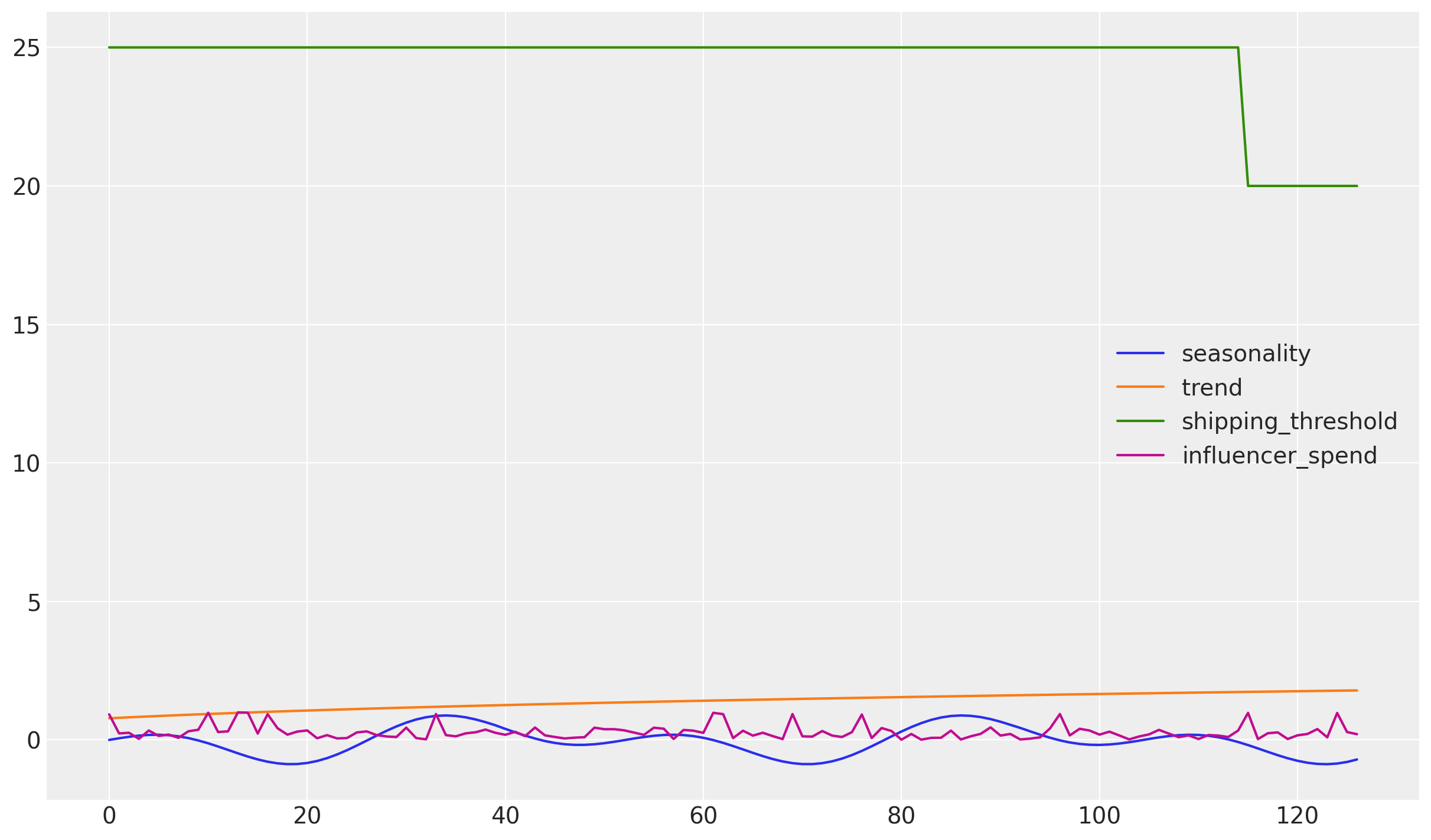
And we can plot the data to get a better sense for the data:
df[["seasonality", "trend", "shipping_threshold", "influencer_spend"]].plot();
Build and fit the MMM#
mmm = MMM(
date_column="date",
target_column="y",
adstock=GeometricAdstock(l_max=8),
saturation=LogisticSaturation(),
channel_columns=["influencer_spend"],
control_columns=["t", "shipping_threshold"],
yearly_seasonality=2,
)
x_train = df.drop(columns=["y"])
y_train = df["y"]
mmm.fit(
X=x_train,
y=y_train,
nuts_sampler="nutpie",
nuts_sampler_kwargs={
"backend": "jax",
"gradient_backend": "jax",
},
)
mmm.sample_posterior_predictive(x_train, extend_idata=True);
Show code cell output
Sampler Progress
Total Chains: 4
Active Chains: 0
Finished Chains: 4
Sampling for 14 seconds
Estimated Time to Completion: now
| Progress | Draws | Divergences | Step Size | Gradients/Draw |
|---|---|---|---|---|
| 2000 | 0 | 0.19 | 63 | |
| 2000 | 0 | 0.19 | 31 | |
| 2000 | 0 | 0.18 | 79 | |
| 2000 | 0 | 0.19 | 31 |
/opt/homebrew/envs/pymc-marketing-dev/lib/python3.12/site-packages/rich/live.py:256: UserWarning: install
"ipywidgets" for Jupyter support
warnings.warn('install "ipywidgets" for Jupyter support')
Sampling: [y]
/opt/homebrew/envs/pymc-marketing-dev/lib/python3.12/site-packages/rich/live.py:256: UserWarning: install
"ipywidgets" for Jupyter support
warnings.warn('install "ipywidgets" for Jupyter support')
Sensitivity analysis and marginal effects#
A multiplicative sweep on influencer spend#
mmm.sensitivity.run_sweep(
var_names=["influencer_spend"],
sweep_values=np.linspace(0, 2, 12),
sweep_type="multiplicative",
)
Show code cell output
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
<xarray.Dataset> Size: 98MB
Dimensions: (chain: 4, draw: 1000, date: 127, sweep: 12)
Coordinates:
* chain (chain) int64 32B 0 1 2 3
* draw (draw) int64 8kB 0 1 2 3 4 5 6 ... 994 995 996 997 998 999
* date (date) datetime64[ns] 1kB 2019-04-01 ... 2021-08-30
* sweep (sweep) float64 96B 0.0 0.1818 0.3636 ... 1.636 1.818 2.0
Data variables:
y (chain, draw, date, sweep) float64 49MB -0.6762 ... 0.363
marginal_effects (chain, draw, date, sweep) float64 49MB 1.464 ... 0.5909
Attributes:
sweep_type: multiplicative
var_names: ['influencer_spend']The code above saves its results into a new group in the mmm.idata called sensitivity_analysis. You can explore it below:
mmm.idata
[autoreload of cutils_ext failed: Traceback (most recent call last):
File "/opt/homebrew/envs/pymc-marketing-dev/lib/python3.12/site-packages/IPython/extensions/autoreload.py", line 325, in check
superreload(m, reload, self.old_objects)
File "/opt/homebrew/envs/pymc-marketing-dev/lib/python3.12/site-packages/IPython/extensions/autoreload.py", line 580, in superreload
module = reload(module)
^^^^^^^^^^^^^^
File "/opt/homebrew/envs/pymc-marketing-dev/lib/python3.12/importlib/__init__.py", line 130, in reload
raise ModuleNotFoundError(f"spec not found for the module {name!r}", name=name)
ModuleNotFoundError: spec not found for the module 'cutils_ext'
]
-
<xarray.Dataset> Size: 33MB Dimensions: (chain: 4, draw: 1000, control: 2, fourier_mode: 4, date: 127, channel: 1) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 ... 998 999 * control (control) object 16B 'shipping_t... * fourier_mode (fourier_mode) object 32B 'sin_1... * date (date) datetime64[ns] 1kB 2019-0... * channel (channel) <U16 64B 'influencer_s... Data variables: (12/16) intercept_contribution (chain, draw) float64 32kB 0.488... adstock_alpha_logodds__ (chain, draw) float64 32kB -0.43... saturation_lam_log__ (chain, draw) float64 32kB 1.358... saturation_beta_log__ (chain, draw) float64 32kB -0.26... gamma_control (chain, draw, control) float64 64kB ... gamma_fourier (chain, draw, fourier_mode) float64 128kB ... ... ... y_sigma (chain, draw) float64 32kB 0.071... channel_contribution (chain, draw, date, channel) float64 4MB ... total_media_contribution_original_scale (chain, draw) float64 32kB 177.3... control_contribution (chain, draw, date, control) float64 8MB ... fourier_contribution (chain, draw, date, fourier_mode) float64 16MB ... yearly_seasonality_contribution (chain, draw, date) float64 4MB ... Attributes: created_at: 2025-08-13T10:19:30.246258+00:00 arviz_version: 0.22.0 inference_library: nutpie inference_library_version: 0.15.2 sampling_time: 14.934990882873535 tuning_steps: 1000 pymc_marketing_version: 0.15.1 -
<xarray.Dataset> Size: 336kB Dimensions: (chain: 4, draw: 1000) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 ... 995 996 997 998 999 Data variables: depth (chain, draw) uint64 32kB 4 6 4 6 5 4 ... 5 4 5 4 5 5 maxdepth_reached (chain, draw) bool 4kB False False ... False False index_in_trajectory (chain, draw) int64 32kB 4 -27 -11 -9 ... 14 -12 16 9 logp (chain, draw) float64 32kB 140.5 140.7 ... 138.8 140.4 energy (chain, draw) float64 32kB -135.1 -136.4 ... -133.7 diverging (chain, draw) bool 4kB False False ... False False energy_error (chain, draw) float64 32kB -0.1269 -0.3253 ... 0.00532 step_size (chain, draw) float64 32kB 0.189 0.189 ... 0.1878 step_size_bar (chain, draw) float64 32kB 0.189 0.189 ... 0.1878 mean_tree_accept (chain, draw) float64 32kB 0.9691 0.9881 ... 0.982 mean_tree_accept_sym (chain, draw) float64 32kB 0.8554 0.8769 ... 0.985 n_steps (chain, draw) uint64 32kB 31 95 15 63 ... 63 15 31 47 Attributes: created_at: 2025-08-13T10:19:30.237387+00:00 arviz_version: 0.22.0 -
<xarray.Dataset> Size: 2kB Dimensions: (date: 127) Coordinates: * date (date) datetime64[ns] 1kB 2019-04-01 2019-04-08 ... 2021-08-30 Data variables: y (date) float64 1kB 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 Attributes: created_at: 2025-08-13T10:19:30.861715+00:00 arviz_version: 0.22.0 inference_library: pymc inference_library_version: 5.25.1 -
<xarray.Dataset> Size: 6kB Dimensions: (channel: 1, date: 127, control: 2) Coordinates: * channel (channel) <U16 64B 'influencer_spend' * date (date) datetime64[ns] 1kB 2019-04-01 ... 2021-08-30 * control (control) <U18 144B 'shipping_threshold' 't' Data variables: channel_scale (channel) float64 8B 0.9919 target_scale float64 8B 3.981 channel_data (date, channel) float64 1kB 0.9189 0.2309 ... 0.2797 0.2041 target_data (date) float64 1kB 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 control_data (date, control) float64 2kB 25.0 0.0 25.0 ... 20.0 126.0 dayofyear (date) int32 508B 91 98 105 112 119 ... 214 221 228 235 242 Attributes: created_at: 2025-08-13T10:19:30.863703+00:00 arviz_version: 0.22.0 inference_library: pymc inference_library_version: 5.25.1 -
<xarray.Dataset> Size: 14kB Dimensions: (index: 127) Coordinates: * index (index) int64 1kB 0 1 2 3 4 5 ... 122 123 124 125 126 Data variables: (12/14) date (index) datetime64[ns] 1kB 2019-04-01 ... 2021-08-30 year (index) int32 508B 2019 2019 2019 ... 2021 2021 2021 month (index) int32 508B 4 4 4 4 4 5 5 5 5 ... 7 7 7 8 8 8 8 8 dayofyear (index) int32 508B 91 98 105 112 119 ... 221 228 235 242 t (index) int64 1kB 0 1 2 3 4 5 ... 122 123 124 125 126 influencer_spend (index) float64 1kB 0.9189 0.2309 ... 0.2797 0.2041 ... ... trend (index) float64 1kB 0.7783 0.7957 0.8126 ... 1.779 1.783 cs (index) float64 1kB -0.01289 0.2258 ... -0.9747 -0.8932 cc (index) float64 1kB 0.006446 -0.1136 ... -0.623 -0.5246 seasonality (index) float64 1kB -0.003223 0.05608 ... -0.7089 epsilon (index) float64 1kB -0.1188 0.06498 ... -0.3317 -0.05244 y (index) float64 1kB 2.561 2.265 1.998 ... 2.734 2.607 -
<xarray.Dataset> Size: 4MB Dimensions: (chain: 4, draw: 1000, date: 127) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 6 7 ... 993 994 995 996 997 998 999 * date (date) datetime64[ns] 1kB 2019-04-01 2019-04-08 ... 2021-08-30 Data variables: y (chain, draw, date) float64 4MB 0.6702 0.5258 ... 0.8099 0.6873 Attributes: created_at: 2025-08-13T10:19:30.859848+00:00 arviz_version: 0.22.0 inference_library: pymc inference_library_version: 5.25.1 -
<xarray.Dataset> Size: 98MB Dimensions: (chain: 4, draw: 1000, date: 127, sweep: 12) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 6 ... 994 995 996 997 998 999 * date (date) datetime64[ns] 1kB 2019-04-01 ... 2021-08-30 * sweep (sweep) float64 96B 0.0 0.1818 0.3636 ... 1.636 1.818 2.0 Data variables: y (chain, draw, date, sweep) float64 49MB -0.6762 ... 0.363 marginal_effects (chain, draw, date, sweep) float64 49MB 1.464 ... 0.5909 Attributes: sweep_type: multiplicative var_names: ['influencer_spend'] -
<xarray.Dataset> Size: 488kB Dimensions: (chain: 4, draw: 1000, control: 2, fourier_mode: 4) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 ... 995 996 997 998 999 * control (control) object 16B 'shipping_threshold' 't' * fourier_mode (fourier_mode) object 32B 'sin_1' ... 'cos_2' Data variables: intercept_contribution (chain, draw) float64 32kB 0.2694 0.2694 ... 0.3854 adstock_alpha_logodds__ (chain, draw) float64 32kB -1.646 -1.646 ... 0.195 saturation_lam_log__ (chain, draw) float64 32kB 0.4302 0.4302 ... 1.437 saturation_beta_log__ (chain, draw) float64 32kB 0.5996 ... -0.08112 gamma_control (chain, draw, control) float64 64kB -0.5422 ... ... gamma_fourier (chain, draw, fourier_mode) float64 128kB 0.3939... y_sigma_log__ (chain, draw) float64 32kB 1.165 1.165 ... -2.623 adstock_alpha (chain, draw) float64 32kB 0.1617 0.1617 ... 0.5486 saturation_lam (chain, draw) float64 32kB 1.538 1.538 ... 4.208 saturation_beta (chain, draw) float64 32kB 1.821 1.821 ... 0.9221 y_sigma (chain, draw) float64 32kB 3.205 3.205 ... 0.07259 Attributes: created_at: 2025-08-13T10:19:30.234662+00:00 arviz_version: 0.22.0 -
<xarray.Dataset> Size: 336kB Dimensions: (chain: 4, draw: 1000) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 ... 995 996 997 998 999 Data variables: depth (chain, draw) uint64 32kB 2 0 2 3 2 3 ... 4 6 4 4 5 4 maxdepth_reached (chain, draw) bool 4kB False False ... False False index_in_trajectory (chain, draw) int64 32kB 2 0 2 1 -3 1 ... -24 8 6 13 9 logp (chain, draw) float64 32kB -2.411e+03 ... 139.3 energy (chain, draw) float64 32kB 2.986e+03 ... -135.3 diverging (chain, draw) bool 4kB False True ... False False energy_error (chain, draw) float64 32kB -9.958 0.0 ... 0.2545 step_size (chain, draw) float64 32kB 1.439 0.2431 ... 0.1878 step_size_bar (chain, draw) float64 32kB 1.439 0.4998 ... 0.1878 mean_tree_accept (chain, draw) float64 32kB 1.0 0.0 ... 0.9721 0.8904 mean_tree_accept_sym (chain, draw) float64 32kB 0.08114 0.0 ... 0.9273 n_steps (chain, draw) uint64 32kB 3 1 3 7 3 ... 63 15 15 63 15 Attributes: created_at: 2025-08-13T10:19:30.240564+00:00 arviz_version: 0.22.0
And of course, you can plot the results! To demonstrate some of the plotting options we’ll plot using the default y-axis scale of absolute sales as well as on a percentage change scale.
fig, ax = plt.subplots(2, 1, figsize=(12, 10), sharex=True)
mmm.plot.plot_sensitivity_analysis(ax=ax[0])
mmm.plot.plot_sensitivity_analysis(percentage=True, ax=ax[1]);
/Users/pablo.deroqueglovoapp.com/pymc-labs/pymc-marketing/pymc_marketing/mmm/plot.py:1336: UserWarning: No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
plt.legend()
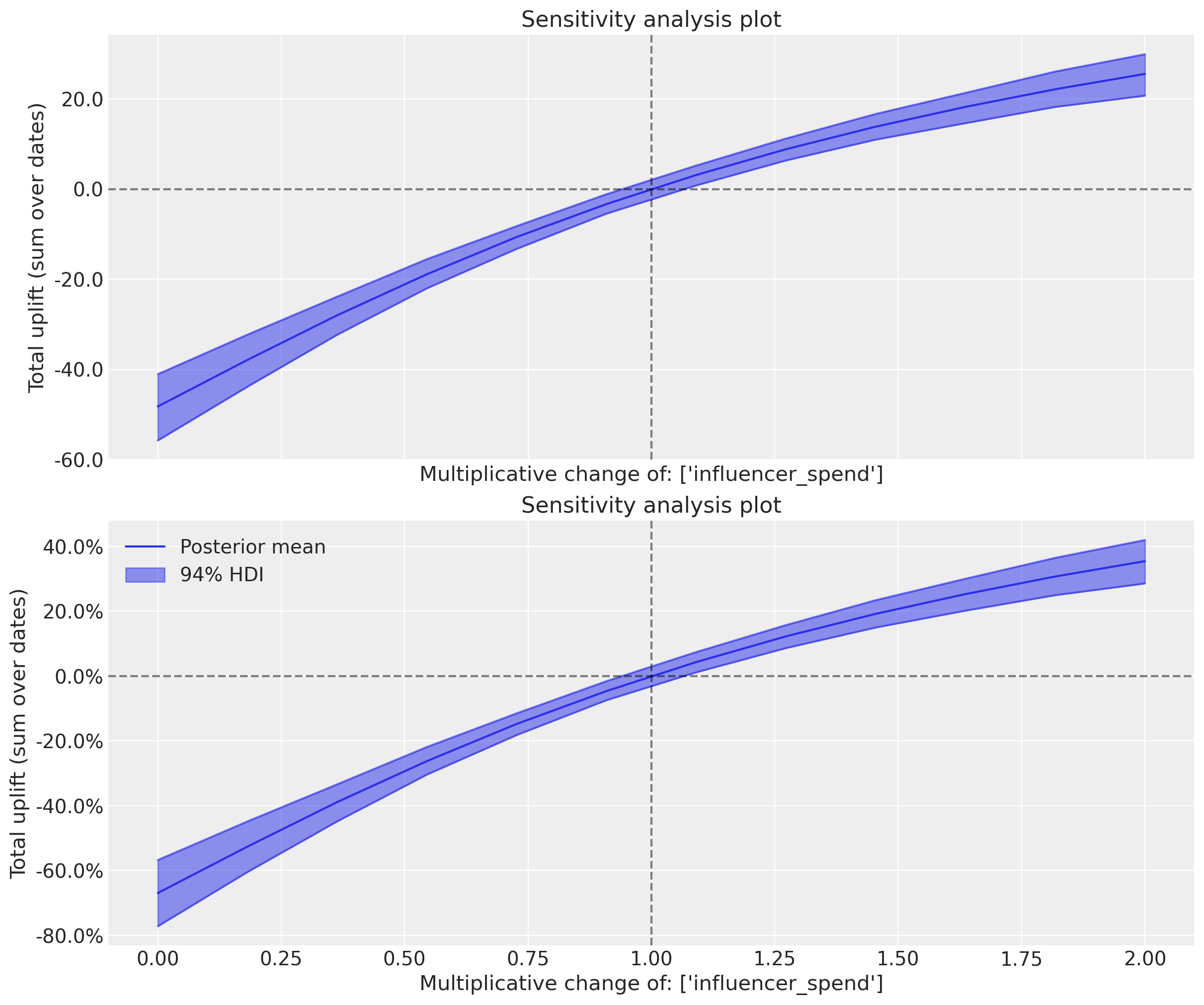
The figure above shows the total expected uplift (it can be positive or negative) for the outcome variable as a function of the sweep values provided. In this case, we used a multiplicative sweep, so the curve is showing how the total outcome would vary if we multiply up (sweep values > 1) or down (sweep values < 1) the influencer spend by the set of values we asked for.
Intuitively, if we multiply the influence spend by 1.0 then on average we expect no change. If we scale the spend down then we expect negative uplift (i.e., lower sales) and if we scale the spend up then we expect positive uplift (i.e., higher sales). The fact that the curve is curved (not linear) is primarily the result of the saturation function on the influencer spend variable.
We can also plot the corresponding marginal effects as below:
mmm.plot.plot_sensitivity_analysis(marginal=True);
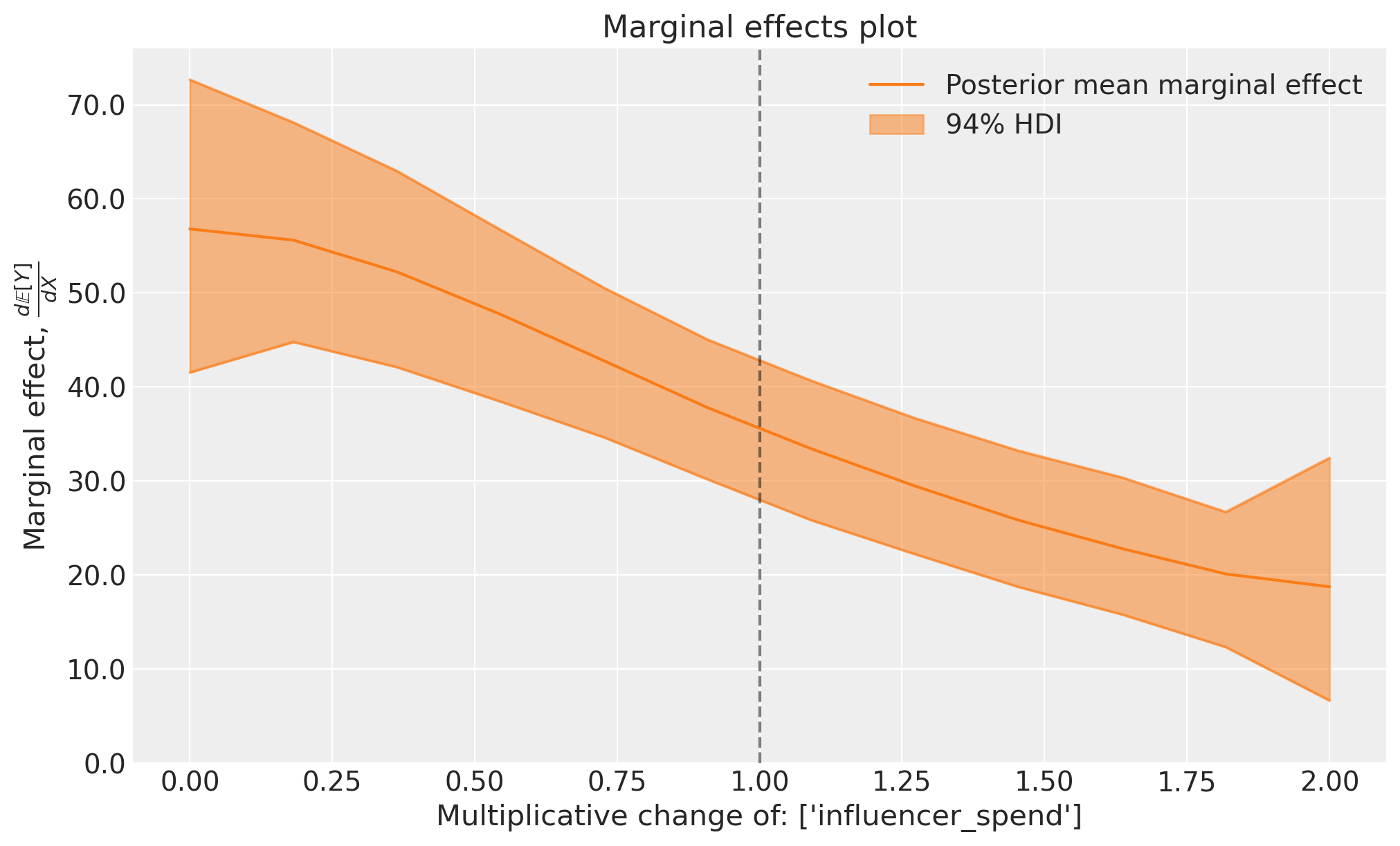
This plot shows the instantaneous rate of change in the outcome variable as we adjust the influencer spend. The y-axis represents the marginal effect, which tells us how much additional sales we expect for a small increase in influencer spend at each point along the sweep values.
We can see that the highest marginal effects occur on the left side of the plot where we the influence spend is zero or very low. The highest incremental/marginal effects are obtained when we go from no spend to some spend. As we would expect from the previous plot, we still get incremental returns at the current spend levels (multiplicative change of 1.0), and are quite far away from totally saturating this channel - the marginal spend doesn’t reduce to near zero even if we consider a 2x increase in spend.
An absolute sweep on influencer spend#
The sensitivity analysis we conducted above involved a multiplicative sweep of the influencer spend variable, meaning we varied it by multiplying it by a set of values. However, we can also conduct a absolute sweep. Here, we set all historical values of the influencer spend variable to fixed values (given in the sweep_values argument) and then compute the expected outcome and marginal effects.
mmm.sensitivity.run_sweep(
var_names=["influencer_spend"],
sweep_values=np.linspace(0, 2, 12),
sweep_type="absolute",
)
Show code cell output
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
<xarray.Dataset> Size: 98MB
Dimensions: (chain: 4, draw: 1000, date: 127, sweep: 12)
Coordinates:
* chain (chain) int64 32B 0 1 2 3
* draw (draw) int64 8kB 0 1 2 3 4 5 6 ... 994 995 996 997 998 999
* date (date) datetime64[ns] 1kB 2019-04-01 ... 2021-08-30
* sweep (sweep) float64 96B 0.0 0.1818 0.3636 ... 1.636 1.818 2.0
Data variables:
y (chain, draw, date, sweep) float64 49MB -0.4471 ... 0.2292
marginal_effects (chain, draw, date, sweep) float64 49MB -0.3712 ... -1.281
Attributes:
sweep_type: absolute
var_names: ['influencer_spend']fig, ax = plt.subplots(2, 1, figsize=(12, 10), sharex=True)
mmm.plot.plot_sensitivity_analysis(ax=ax[0])
mmm.plot.plot_sensitivity_analysis(marginal=True, ax=ax[1]);
/Users/pablo.deroqueglovoapp.com/pymc-labs/pymc-marketing/pymc_marketing/mmm/plot.py:1336: UserWarning: No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
plt.legend()
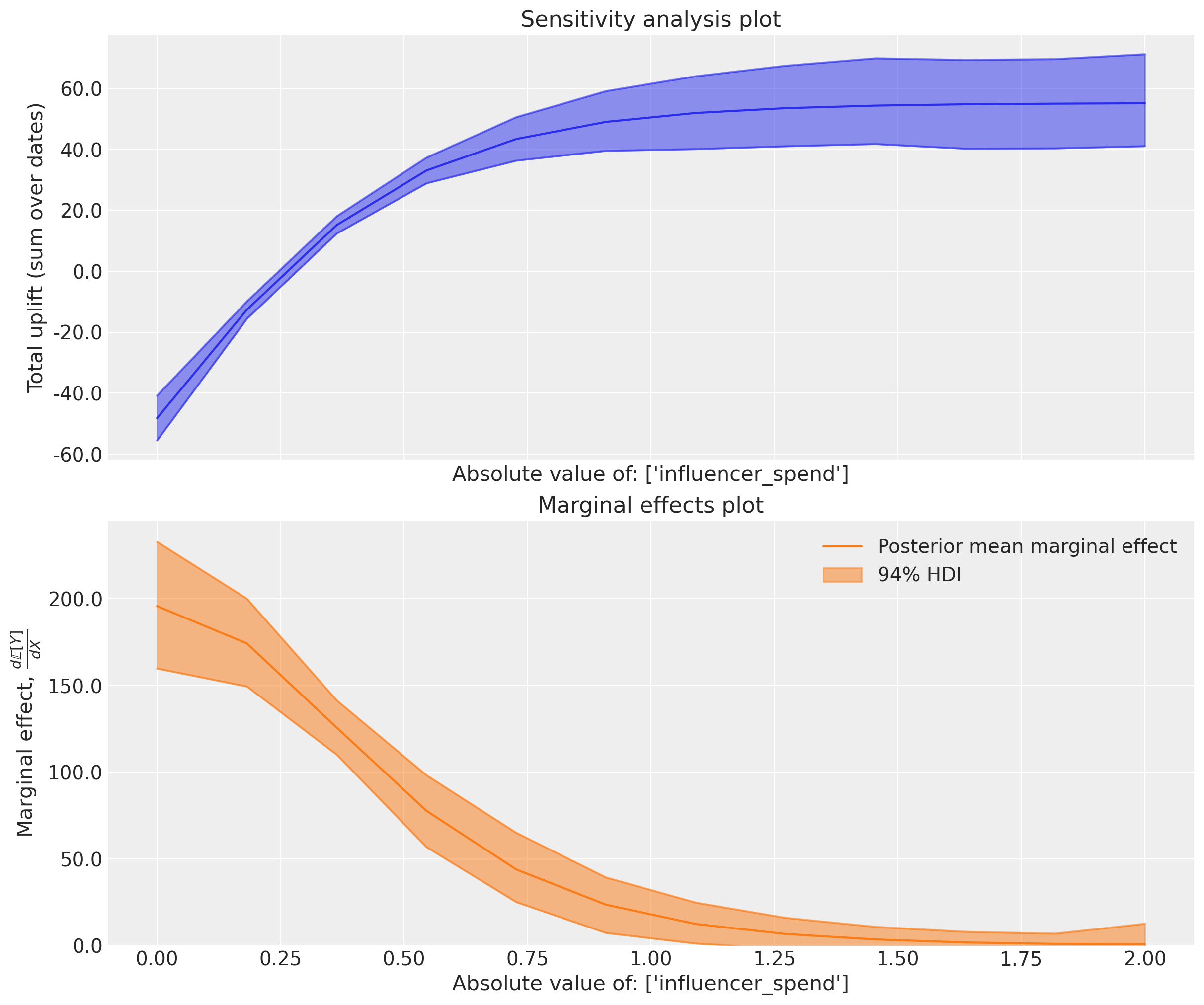
The results of the absolute sweep are comparable to (but not the same as) the multiplicative sweep. They key difference in what we are doing is that we overwrite the historical influencer spend values with a constant spend value (one value for each point in the sweep). This means we are not considering a ‘realistic’ scenario where spend fluctuates over time, but rather a hypothetical scenario where we set the spend to a fixed value for all weeks in the dataset.
We can see the change in the plots as well. The top plot is similar to, but not exactly the same as the saturation curve of influencer spend. Notice that there is a certain fixed spend level where the uplift is about zero. This is interesting - we can interpret this as saying that the total sales in the actual scenario would also have been about the same if we had spent that amount (constantly over time) on influencer marketing.
The top plot nicely shows the saturating quality of the saturation function, and the bottom plot shows that as we approach saturation, the marginal effects drop to near zero.
An additive sweep on influencer spend#
We can also consider a sweep of additive changes to the influencer spend variable. This means we adjust the historical values of the influencer spend by adding a fixed amount (given in the sweep_values argument) and then compute the expected outcome and marginal effects.
Warning
Note that care needs to be taken with an additive sweep. It would be easy to apply a negative peterbation which then actually results in negative spend values which have no meaningful interpretation. So it is worthwhile exploring the actual spend values before deciding on the sweep values to be used.
In our case, the minimum spend values is $0, so we will not considervalues in the sweep.
df["influencer_spend"].min()

mmm.sensitivity.run_sweep(
var_names=["influencer_spend"],
sweep_values=np.linspace(0, 2, 12),
sweep_type="additive",
)
Show code cell output
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
<xarray.Dataset> Size: 98MB
Dimensions: (chain: 4, draw: 1000, date: 127, sweep: 12)
Coordinates:
* chain (chain) int64 32B 0 1 2 3
* draw (draw) int64 8kB 0 1 2 3 4 5 6 ... 994 995 996 997 998 999
* date (date) datetime64[ns] 1kB 2019-04-01 ... 2021-08-30
* sweep (sweep) float64 96B 0.0 0.1818 0.3636 ... 1.636 1.818 2.0
Data variables:
y (chain, draw, date, sweep) float64 49MB -0.03469 ... 0....
marginal_effects (chain, draw, date, sweep) float64 49MB 1.17 ... 0.02177
Attributes:
sweep_type: additive
var_names: ['influencer_spend']fig, ax = plt.subplots(2, 1, figsize=(12, 10), sharex=True)
mmm.plot.plot_sensitivity_analysis(ax=ax[0])
mmm.plot.plot_sensitivity_analysis(marginal=True, ax=ax[1]);
/Users/pablo.deroqueglovoapp.com/pymc-labs/pymc-marketing/pymc_marketing/mmm/plot.py:1336: UserWarning: No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
plt.legend()
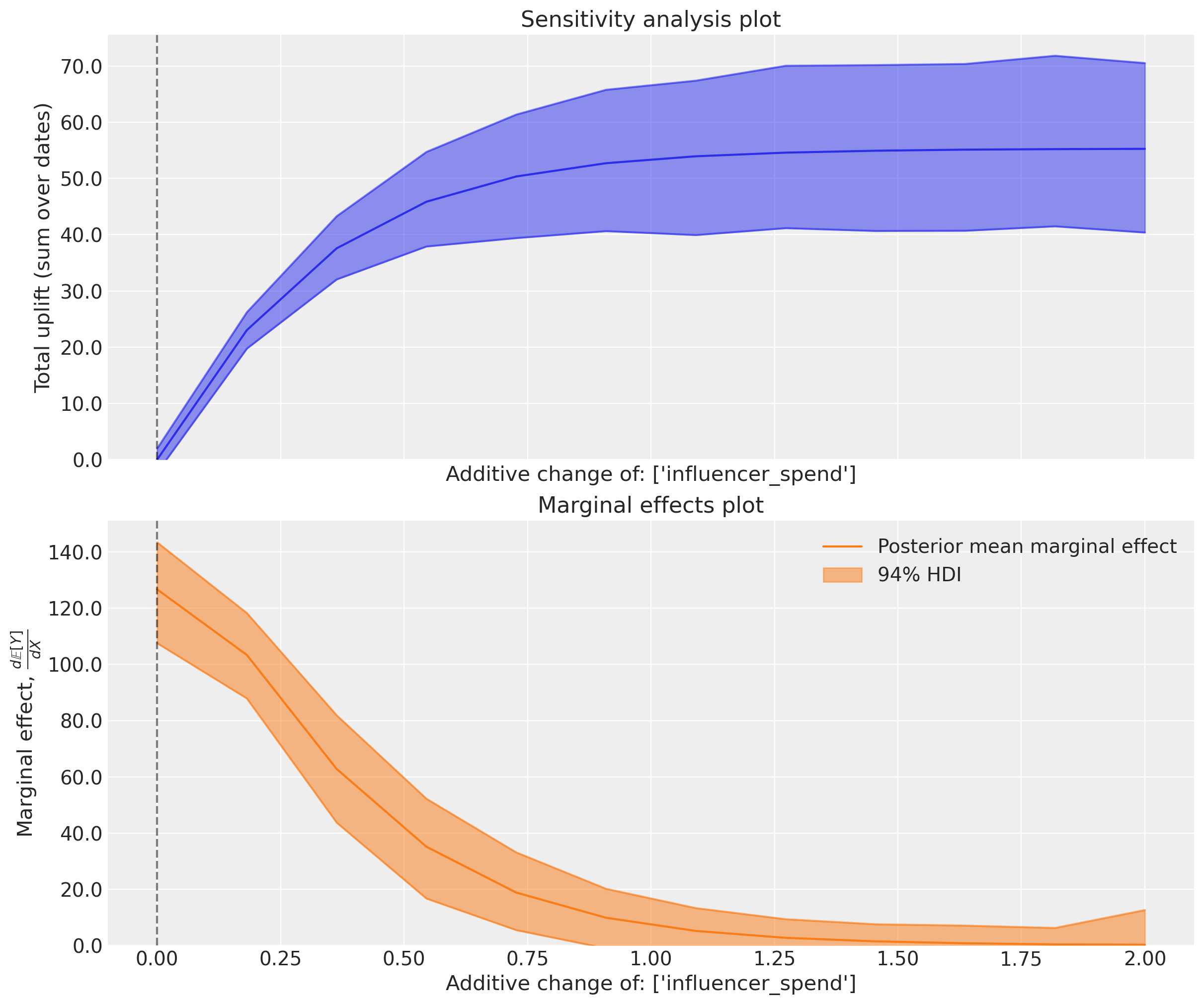
These plots show the expected uplift and marginal effects. We get a similar general pattern of results - if we consider scenarios where we had spent progressively more, then we would get positive uplift, but as we reach a certain level of spend, the advertising channel saturates and the marginal effects drop to near zero.
Sensitivity analysis on the free shipping threshold#
We’ve had a thorough look at the influencer spend variable and we’ve got some interesting insights into how it affects the outcome (sales) under different counterfactual scenarios.
But we can also do the same for the free shipping threshold driver. The reason why this is interesting in our example is because this driver is assumed to have linear effects on the outcome, with no saturation or adstock function applied.
We won’t exhaustively run through all the different sweeps we can do, but we will just demonstrate an absolute sweep.
mmm.sensitivity.run_sweep(
var_names=["shipping_threshold"],
sweep_values=np.linspace(0, 1, 12),
sweep_type="absolute",
)
Show code cell output
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
<xarray.Dataset> Size: 98MB
Dimensions: (chain: 4, draw: 1000, date: 127, sweep: 12)
Coordinates:
* chain (chain) int64 32B 0 1 2 3
* draw (draw) int64 8kB 0 1 2 3 4 5 6 ... 994 995 996 997 998 999
* date (date) datetime64[ns] 1kB 2019-04-01 ... 2021-08-30
* sweep (sweep) float64 96B 0.0 0.09091 0.1818 ... 0.9091 1.0
Data variables:
y (chain, draw, date, sweep) float64 49MB 0.4111 ... 0.428
marginal_effects (chain, draw, date, sweep) float64 49MB -0.6963 ... -1.128
Attributes:
sweep_type: absolute
var_names: ['shipping_threshold']fig, ax = plt.subplots(2, 1, figsize=(12, 10), sharex=True)
mmm.plot.plot_sensitivity_analysis(ax=ax[0])
mmm.plot.plot_sensitivity_analysis(marginal=True, ax=ax[1]);
/Users/pablo.deroqueglovoapp.com/pymc-labs/pymc-marketing/pymc_marketing/mmm/plot.py:1336: UserWarning: No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
plt.legend()
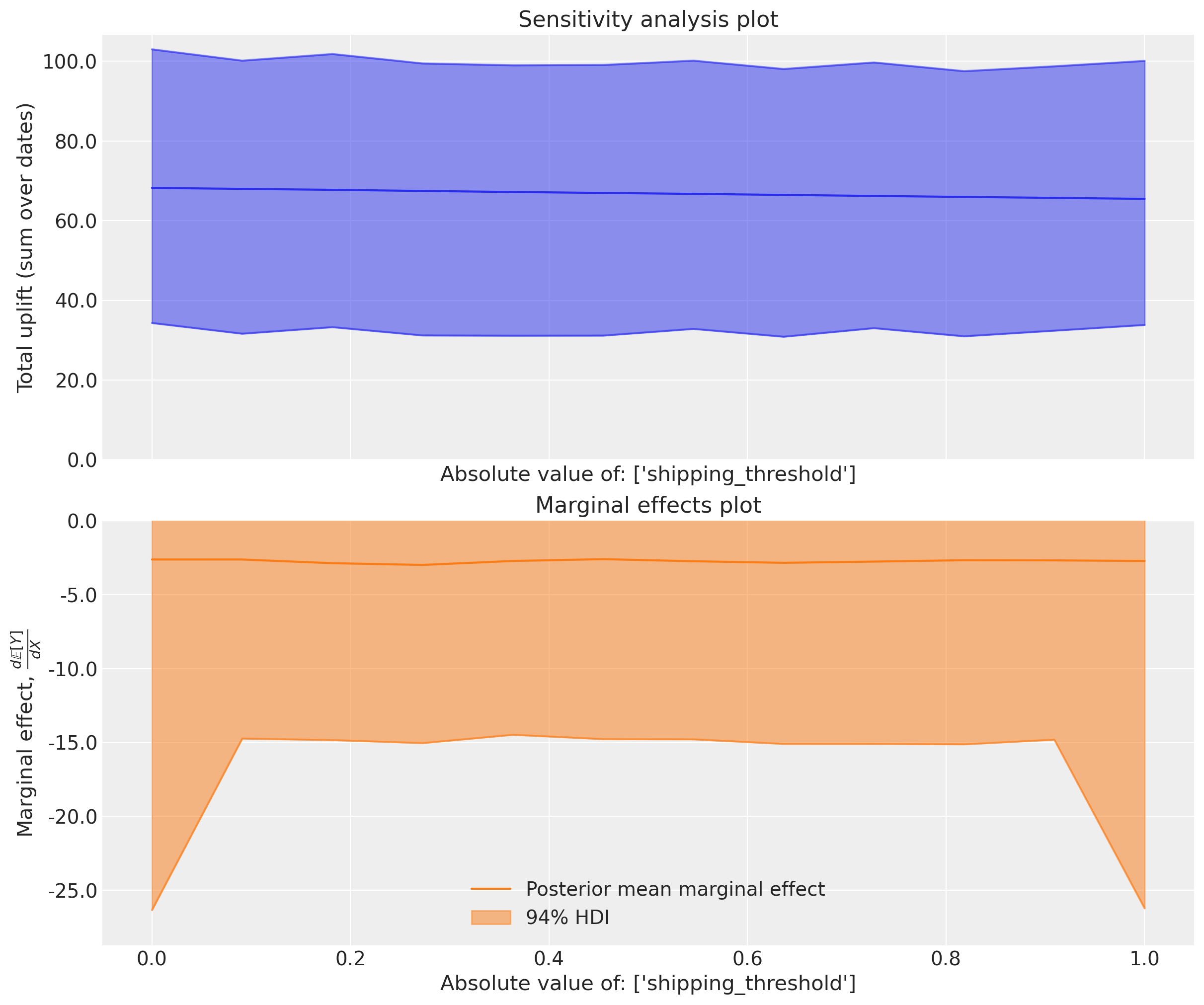
We can see the linear nature of the effects of the free shipping threshold on the outcome variable. The expected uplift is positive when we lower the threshold (people buy more when shipping is free), and the marginal effects are constant across the sweep values. This is because we assumed a linear relationship between the free shipping threshold and sales, so the marginal effect does not change as we adjust the threshold. The constant negative value is equal to the change in uplift as we increase the shipping threshold by $1.
We can verify this by changing the sweep step size and seeing that we get identical marginal effects estimates (albeit with numerical estimation error).
mmm.sensitivity.run_sweep(
var_names=["shipping_threshold"],
sweep_values=np.linspace(0, 1, 30),
sweep_type="absolute",
)
Show code cell output
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
Sampling: [y]
<xarray.Dataset> Size: 244MB
Dimensions: (chain: 4, draw: 1000, date: 127, sweep: 30)
Coordinates:
* chain (chain) int64 32B 0 1 2 3
* draw (draw) int64 8kB 0 1 2 3 4 5 6 ... 994 995 996 997 998 999
* date (date) datetime64[ns] 1kB 2019-04-01 ... 2021-08-30
* sweep (sweep) float64 240B 0.0 0.03448 0.06897 ... 0.9655 1.0
Data variables:
y (chain, draw, date, sweep) float64 122MB 0.4907 ... 0.3568
marginal_effects (chain, draw, date, sweep) float64 122MB -4.118 ... -4.627
Attributes:
sweep_type: absolute
var_names: ['shipping_threshold']fig, ax = plt.subplots(2, 1, figsize=(12, 10), sharex=True)
mmm.plot.plot_sensitivity_analysis(ax=ax[0])
mmm.plot.plot_sensitivity_analysis(marginal=True, ax=ax[1]);
/Users/pablo.deroqueglovoapp.com/pymc-labs/pymc-marketing/pymc_marketing/mmm/plot.py:1336: UserWarning: No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
plt.legend()
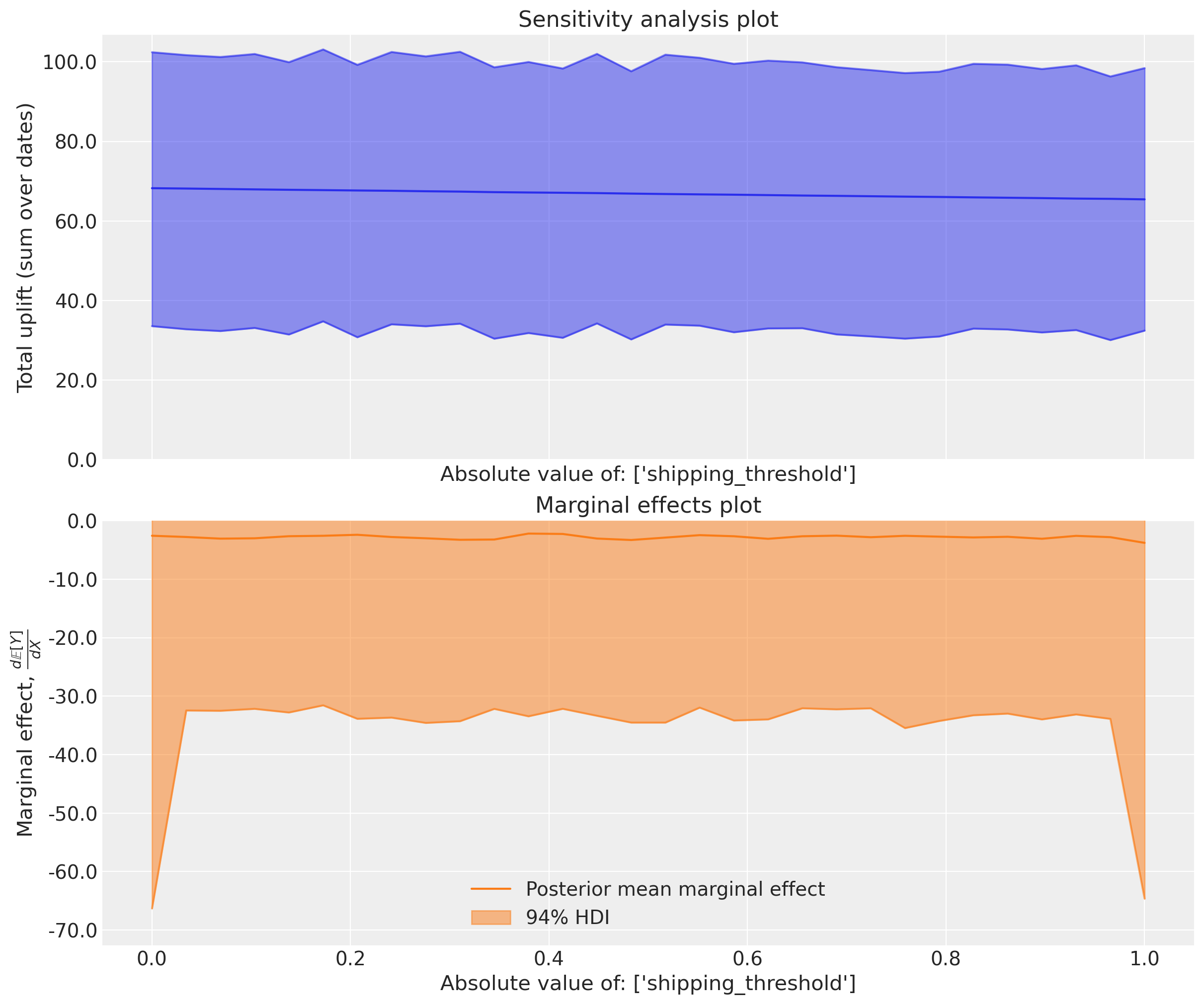
Tip
Why should I be interested in a straight line and a flat line? These are the kinds of plots that you can run through to get a sense check of whether the model is behaving as expected.
Maybe you (or a client) realises that a negative linear relationship between shipping threshold and sales is too simplistic. This can then drive model iteration and improvement - you could explore alternative functional forms for example.
Summary#
We’ve introduced a simple but powerful tool for probing deeper into your MMM results. You can explore a sweep of perterbations to one or more driver variables and compute the expected outcomes and marginal effects for each scenario. You can consider different forms of peterbation, here we’ve shown multiplicative, absolute and additive sweeps.
This allows you to answer “what if” questions with precision and clarity, providing actionable insights into how different levers affect your business outcomes. You can produce simple and interpretable plots that you can use to communicate how the model works and get sense-checks on the model’s behaviour and assumptions.
#
%load_ext watermark
%watermark -n -u -v -iv -w -p pymc_marketing,pytensor
Last updated: Tue Jul 29 2025
Python implementation: CPython
Python version : 3.12.11
IPython version : 9.4.0
pymc_marketing: 0.15.1
pytensor : 2.31.7
matplotlib : 3.10.3
pandas : 2.3.1
pymc_marketing: 0.15.1
arviz : 0.22.0
graphviz : 0.21
numpy : 2.2.6
Watermark: 2.5.0